
Generative AI offers numerous opportunities for untapping insights and driving process automation from unstructured data. Through data summarization, labeling, and similarity searches, Generative AI enables organizations and data professionals to innovate and unlock value from unstructured data. These opportunities range from closely monitoring customer interactions on text and audio to flagging suspicious transactions, automatically labeling product catalogs, and creating organization-wide knowledge bases. Additionally, Generative AI also facilitates the development of orchestration tools that automate these tasks through agent-based systems, known as Agentic AI.
A very important aspect of extracting value from data means processing the data efficiently, especially when dealing with large volumes. Teradata, due to its Massive Parallel Processing (MPP) technology, has always been known for its high performance. In the age of Generative AI, this reputation remains strong as Teradata innovates with a high-performance Enterprise Vector Store, that seamlessly bridges the high performance of Teradata Vantage with Large Language Models offered through providers such as AWS, Microsoft Azure, and NVIDIA NIM™.
Teradata Enterprise Vector Store offers a single API to ingest and chunk text, generate embeddings and build indexes, all inside your trusted Teradata Vantage system.
In this article, we'll show you how the new Teradata Vantage vector store offers the flexibility to balance accuracy and performance, unlocking a wide range of enterprise use cases.
Let's start with a quick review about indexes and search in the familiar context of structured data.
Indexes and search on structured data
Imagine you are visiting your local library searching for a specific book. The first step you would take is to consult the library’s catalog, which will point you to where the book is located. Without the library catalog, you would need to check each book in the library one by one until, hopefully soon, you find the book you are looking for. Let’s ignore, for now, that everything is organized by genre (which reduces your search time).
SELECT NAME
FROM USERS
WHERE AGE >= 30
The database engine would need to go through each record to find all the users that meet the condition. This process is called a full table scan, and it should be avoided in queries that run frequently on large datasets.
To prevent this situation, especially if this type of search is common, your Database Administrator (DBA) will create an index. An index orders the data in a specific column, in this case AGE and includes pointers to specific locations where data with specific values can be found.
With this index the database engine doesn’t need to go through all rows in the table of interest to find the data needed by the query. The index is the equivalent of the library’s catalog.
Unstructured data and the magic of vectors
Now, returning to our library analogy, let’s say you don’t want to find a specific book, such as The Fellowship of the Ring, but rather books similar to The Lord of the Rings saga. In this case, since you don’t have a specific title in mind, the library catalog isn’t as useful. However, the library’s layout, which groups similar books together, solves a big part of your problem. A quick read of the back covers of books in the section where the books of the Lord of the Rings saga are located will be all that you need. This similarity is subjective; it depends largely on both the judgment of the librarian and your own.
Like the problem above, use cases that rely on unstructured data focus on finding similarities rather than equalities. Building knowledge bases for Retrieval-Augmented Generation (RAG) systems, which enhance LLMs' ability to generate relevant responses, detecting suspicious transactions through log pattern matching, and the labeling and grouping of text fields, are all examples of such problems.
We have always had methods to deal with these types of problems, mostly within the field of Natural Language Process (NLP). These methods, however, have been difficult to scale, but this all changed with the advent of commercial use Large Language Models (LLMs) that are able to generate vector embeddings.
Embeddings are representations of unstructured data, primarily text, that lie at the core of, and that power Generative AI. Embeddings are numerical representations that large language models (LLMs) generate for a given piece of text. The values in these embeddings capture the characteristics, relations and features of the data.
Embeddings can be visualized as vectors pointing to specific locations in a multidimensional space. Texts with similar features produce embeddings that are positioned closer together in this multidimensional space, as shown in the image below.
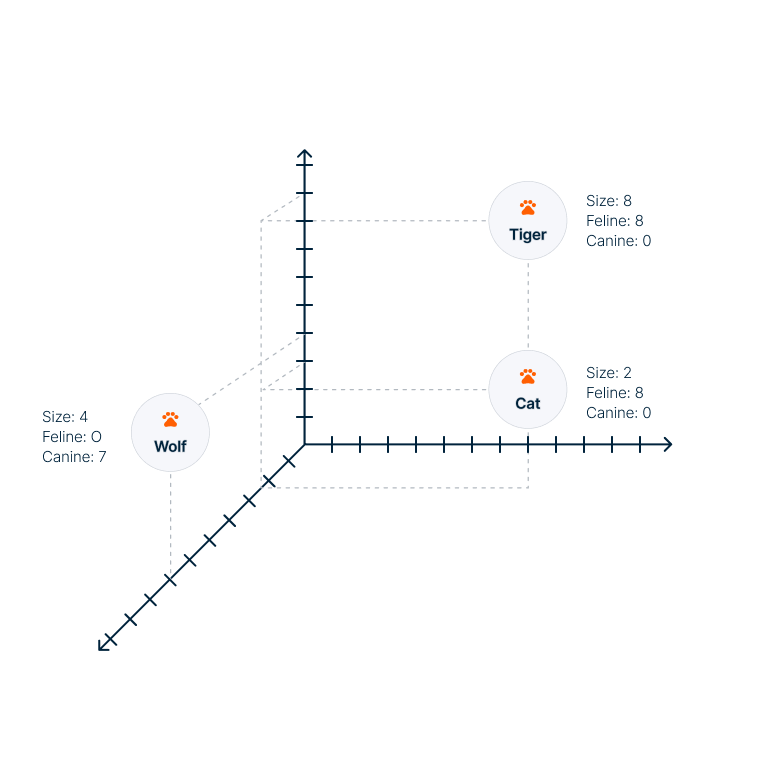
Illustration of a multidimensional space and sample embeddings
A tiger and cat are closer together, while a wolf is farther away. The coordinates are provided according to a hypothetical space with three dimensions with defined meanings (size, feline, and canine), only as an illustration, actual embeddings are much larger and the features the dimensions represent are not specifically defined.
Because embeddings are vectors in a space, the similarity between them can be calculated precisely and objectively with measures such as Euclidean distance, dot product or cosine similarity. How do we build the equivalent of our library’s book classifier utilizing vectors then?
We need three components: an LLM capable of generating embeddings based on book abstracts, a mechanism for storing the embeddings, and an index that efficiently finds similarities. Teradata Enterprise Vector Store capabilities and the Teradata Generative AI Python library provide convenient access to these components through a user-friendly Application Programming Interface (API).
Building a book classifier with Teradata Enterprise Vector Store
Building the Vector Store
We are starting with a set of book abstracts already ingested into our Teradata Vantage System. In total we have 80 books with their corresponding abstracts taken from Kaggle’s Book Genre Prediction dataset.
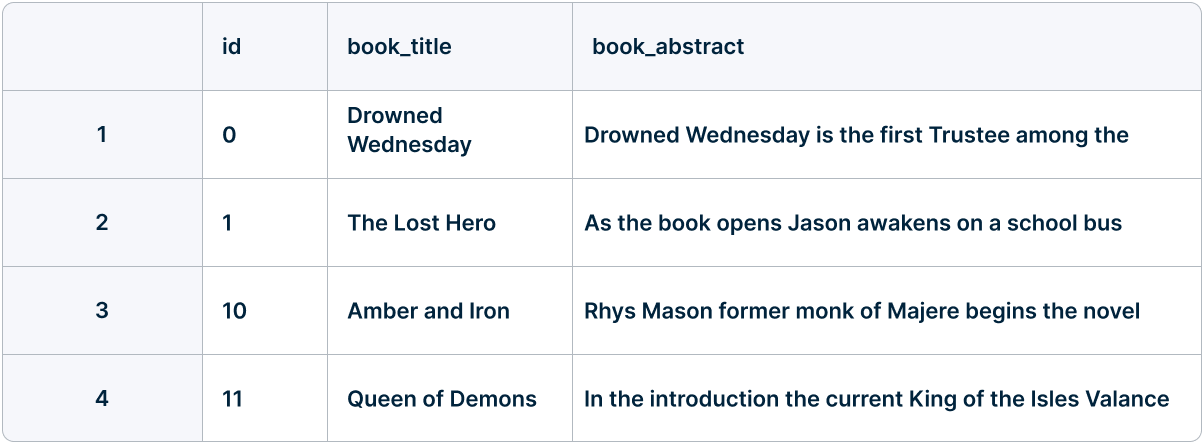
Sample data on book abstracts
This data is stored in the `book_samples` table within a test project's database. We will generate the embeddings on the `book_abstract` column for each book, which is identified by a corresponding `id`.
We then instantiate a Teradata Enterprise Vector Store through Teradata GenerativeAI API.
from teradatagenai import VectorStore
vs = VectorStore(name="library_example")
Teradata Enterprise Vector Store is integrated with Large Language Models (LLMs) for embedding generation and chatbot functionality. In the system utilized in this example, these LLMs are provided through the deployment of NVIDIA NIM.
Teradata Enterprise Vector Store instantiated in a system integrated with NVIDIA NIM
At this point, we have merely instantiated the VectorStore class. To create the vector store, we define the data source for vector generation by specifying the database, table, and columns of interest (mentioned above), and configure the corresponding index.
Searching on vectors without an index is like searching a library without genre divisions; to find similar books, you’d need to compare each book individually. Similarly, finding vector similarities without an index involves looking through all the vectors and computing the distances between your search vector and each potential candidate, this is laborious and time consuming.
One technique for building vector similarity indexes involves reducing the search space by identifying clusters of similar vectors. In our library example this is equivalent to grouping the books by genre. We need a balanced distribution of books across our chosen genres. An unbalanced distribution would lead to unnecessarily long searches when trying to place a new book near the most similar ones in its genre.
The cluster-based algorithm described above, called KMEANS, is very simple to illustrate and understand. Therefore, we base our illustration on this technique. Teradata Enterprise Vector Store also supports Hierarchical Navigable Small World (HNSW) indexing, a graph-based approach to achieve a similar purpose.
Initially, we don’t have predefined genres, so we need to make some assumptions to create them. The first assumption is deciding on an arbitrary number of genres beforehand. A good rule of thumb is to choose a higher number if there are many books to classify. Let’s say we decide on four genres.
In Teradata Enterprise Vector Store API this is a parameter that can be defined as follows:
train_numcluster = 4
We’d start by picking four random books from the room and examining their covers. Based on what we see, we’d assign them to four piles. Each initial book becomes the anchor for a genre. Next, we’d go through the rest of the books, read their covers, and assign each one to a pile according to how similar we judge its abstract to be compared to the pile’s anchor.
This process is unlikely to yield a good classification at first, but it can be refined iteratively. After the first pass, we might decide that other books would make better anchors, so we will make those books the anchors and we will proceed to redistribute the books once again.
When building a similarity index for vectors, we follow a comparable process of classification. We provide the index creation algorithm with the number of clusters we want and the number of iterations to run. The key difference is that this process is executed with mathematical precision.
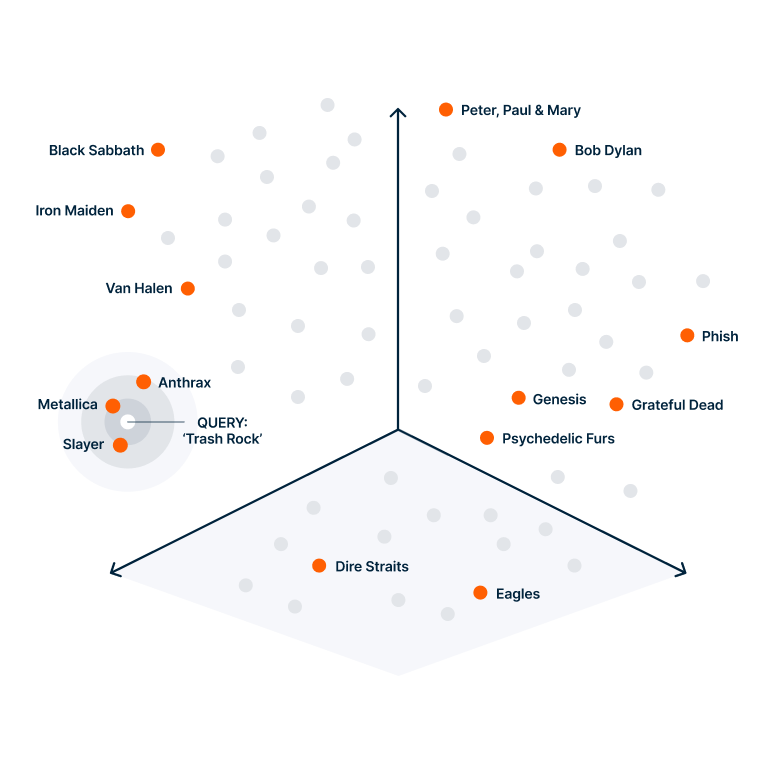
Clusters of music genres with their corresponding vectors
The vectors designated as anchors for each cluster, formally called centroids, are chosen randomly at the beginning. After each pass, however, the centroids are updated by averaging the vectors within each cluster. This iterative process allows the clusters to evolve up to a point where new iterations don’t produce any meaningful change, this is called convergence. At this point we’d found a layout that optimally distributes vectors across the specified number of clusters.
Each pass involves, as you might expect, a complete run of distance calculations across all vectors. Initially, this computational expense is justified by the quality of the resulting index. However, at some point, the law of diminishing returns kicks in, and the incremental improvement in index quality no longer justifies the extra computation from additional iterations. Choosing the number of iterations is a tradeoff regarding how good an index we want to produce and how fast we want the index to be built. This last consideration is very important if we expect the index to be rebuilt often due to new data being added.
The maximum number of iterations and the precision threshold (convergence) are parameters that can be defined in Teradata’s Enterprise Vector Store API.
max_iternum = 50
stop_threshold = 0.0395 #Default value, measures how much the vectors moved from their position in the previous iteration.
The beauty of the index is that, once created, it eliminates the need to perform full distance calculations on the entire vector space when searching for similarity between vectors. Instead, you compute the distance of your search vector against the centroids, find the closest one, and then calculate distances within that centroid’s cluster.
Putting it all together we can create our vector store, pointing to the relevant data and defining the characteristics of our index.
vs.create(embeddings_model="nvidia/nv-embedqa-mistral-7b-v2",
chat_completion_model="meta/llama-3.1-8b-instruct",
search_algorithm='KMEANS',
database_name='daniel_test',
object_name='book_library',
key_columns=['id'],
data_columns=['book_abstract'],
vector_column='VectorIndex',
train_numcluster = 4,
max_iternum = 50,
stop_threshold = 0.0395,
metric='COSINE')
In this case, the cluster distribution generated by the index appears reasonable. Three clusters are very well balanced, while the fourth one could be explained by books in a less popular genre.
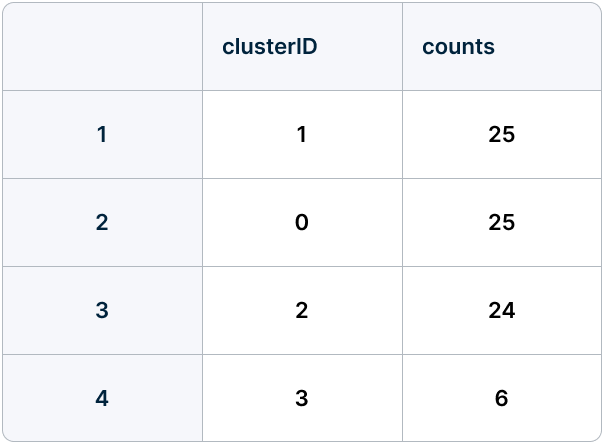
Cluster distribution based on book abstracts
Performing similarity searches
The Teradata Enterprise Vector Store API provides a convenient interface for performing searches. This functionality can be used in our example to find which books are more like one another, based on their abstracts, or to place a new arrival in a specific cluster, again based on its abstract.
Provided the abstract for Pride and Prejudice by Jane Austen for example:
“Since its immediate success in 1813, Pride and Prejudice has remained one of the most popular novels in the English language. Jane Austen called this brilliant work "her own darling child" and its vivacious heroine, Elizabeth Bennet "as delightful a creature as ever appeared in print." The romantic clash between the opinionated Elizabeth and her proud beau, Mr. Darcy is a splendid performance of civilized sparring.”
We can look for the most similar books in our data:

Teradata Enterprise Vector Store generating a similarity search based on the index
On this result we can filter by the 3 most similar books in our data:

Top 3 similar results to Pride and Prejudice
The most similar result is the book we are comparing to itself. The other top results are reasonably similar books, considering we only produced vectors based on the abstracts. It’s worth noting that you might not always find the true nearest neighbors to your search vector. The quality of the index depends on the assumptions made during its construction—namely, the number of clusters and the number of iterations. The number of clusters might not have been ideal for the data, or the number of iterations might not have allowed the clusters to fully converge.
Still, the approximate nearest neighbors produced by the index are sufficient for many use cases. And if, in a specific instance, you absolutely need the exact nearest neighbors, you can always perform a full comparison search.
The ability to efficiently store vectors, index vectors and run similarity searches is key for the implementation of enterprise initiatives regarding Generative AI. Many point solutions have dedicated capabilities for this. For Teradata customers, however, all these capabilities are available in Teradata Vantage. No extra vendors, no extra vetting processes, if you happen to be in a regulated industry, there’s no need to pay for another platform.
Just like this example, it’s also possible to ingest data directly from PDF files.
Visit the Teradata Enterprise Vector Store page to learn more and explore the value that untapping insights from unstructured data can bring to your organization.