
Advances in analytics and Artificial Intelligence (AI) have been adopted at a rapid pace. It is also driving cloud costs through the roof, so why not leverage predictive AI capabilities with the objective of maximizing the benefits of cloud compute resources while minimizing expenses?
Many cloud services offer guidance in managing costs through manually monitoring, observing, and experimenting to address cost overruns. The most common cloud payment model is pay-as-you-go in which you are charged for the time your compute instance is turned on, therefore the largest contributor to cloud costs is time.
Compute resources cost prediction methods can automate the efficient use of compute resources to complete the most work in the shortest time and the least compute resources.
In the case of analytic platforms, the algorithm can classify compute resource cost in terms of time, leverage a generative AI approach to dynamically rewrite queries, and react to workload conditions to maximize the throughput of work with the least number of compute resources. This would get more work done in the least amount of time contributing to lower cloud costs.
Understanding Cost in Computer Architecture
To begin we must understand the costs associated with compute resources in relation to time.
CPU
Let’s begin with the primary compute resource; the central processing unit (CPU). There is also the graphics processing unit (GPU) which specializes in repetitive processing but for simplicity we’ll use the CPU as a reference. In your cloud compute instance, you may see the CPU being referenced as a core or as a vCPU. This means that the physical processor component may contain multiple virtual processors.
Each second that a CPU is running is time that the CPU is available to perform tasks and is referred as a CPU second. If you have many CPUs running concurrently in parallel, then the total number of CPUs running in each real-time second provides a measure of capacity. For example, if you have 8 CPUs then for every real-time second you have 8 CPU seconds of capacity. In one minute, you would have 60 seconds times eight for a total of 480 CPU seconds.
The CPU can be busy executing tasks for processing data, but it can also be idle or waiting for another resource which is unproductive and impacts the length of time to process data. The objective is to keep the CPU busy with productive activity processing data and reduce the nonproductive time as much as possible thereby maximizing compute efficiency.
In each period, you can measure how many CPU seconds were productive (busy) and how many CPU seconds were nonproductive (idle or waiting). You can get a ratio by dividing the busy CPU seconds by the total CPU seconds.
The faster a CPU can complete productive tasks the higher the throughput of work.
Storage
Storage refers to the resources responsible for holding data. Data in storage is doing nothing. Data is useful only when it is moved to the CPU for processing.
The components used for storage will determine the capacity it can hold and whether the storage is volatile (data is erased when power is turned off) or non-volatile (data is permanently stored). The components may also have different speeds at which it can input / output (I/O) data. On-board memory typically used for cache is the fastest, Solid State Drive (SSD) is almost as fast since it is composed of flash memory, and Hard Disk Drive (HDD) is by far the slowest with mechanical arms and heads needing to seek data on a rotating magnetic disc.
The faster the I/O and the greater the data cache effectiveness, the higher the throughput of work.
Network
The network serves as the interconnect between the CPU, storage, and external peripherals. It is responsible for transporting the data to its destination. The speed at which the data is transmitted is impacted by the distance between the two points of contact. The further the distance the longer the time it takes to transfer the data, known as latency. This can be optimized with adjustments to compensate for latency to generate higher throughput.
The faster and more finely tuned the network the higher the throughput of work.
Cost Optimization
The approach to predicting costs comes from predictive AI techniques. The objective of maximizing compute resources at the lowest cost involves the implementation of costing methods and discovery of the platform configuration such as the number of instances, number of parallel processing units, CPU speed, storage I/O capacity and network throughput rates. Each of these costing methods account for independent scaling factors between compute and storage.
In addition to the platform the application characteristics also need to be included such as the estimated cardinality or number of rows to retrieve, where to retrieve them, access path via parallel distribution or via indexing strategies, demographics of the data in network attached object storage vs direct attached storage, and statistical representation of the data distribution.
Additionally, it would apply a generative AI approach to rewriting submitted queries to optimize the use of resources such that the rewritten query will produce the same result and applies best practices to be less costly as the original query.
Heuristics are used to dynamically adjust the CPU, I/O, and Network costs. This is a process of discovery and learning from the data and fitting functions to generate cost predictions for previously unseen data. This does not just rely on historical inferences; it also includes evaluating the current conditions of the platform for dynamic decision making to optimize the resources for the volume of work presently active.
Cost validation is a dynamic model evaluation feedback loop to verify that a collection of cost prediction features for specific platform configurations contributes to a high confidence in prediction accuracy to maximize the benefits of the resources at the lowest cost. Heuristics cost therefore is only incurred based on cost validation recommendations.
Cost prediction is extended when accessing data from external platforms or external file systems by using the features of the external resources. File or table formats will provide information on best costs for accessing, distributing, and processing data. Conversely, remote query optimization can be applied to maximize efficiency of the remote platform that manages the data.
When Can We Expect This?
This level of sophistication to optimize cloud costs will take many of the cloud analytic platforms years if not decades to develop.
Fortunately, there is an innovative forward-thinking cloud analytic platform that over the last four decades has been implementing and maturing many of the capabilities needed to support AI going forward and continues to modernize them for the future.
Teradata implemented the Optimizer Cost Estimation Subsystem (OCES) [1], Incremental Planning and Execution (IPE) [2], and Query Rewrite Subsystem (QRS) [3] decades before the cloud was born. It is designed to use the right compute for the right job. It is frequently updated to continue to mature and modernize. Many updates implement features in preparation for future innovations to dynamically adapt to modern and future trends that are still in incubation.
This is unlike the modern cloud analytic platforms that separate each individual workload into its own cluster unable to completely and efficiently consume all the available resources generating excessive cloud waste in costs associated with unused resources. Additionally, the use of multiple clusters increases the number of CPUs being utilized and contributes to carbon emissions. The number of CPUs, the CPU power rating, and the CPU second utilization is needed to calculate the carbon emissions expressed as carbon dioxide equivalents (metric tons CO2-eq). These platforms are still working to catch up to Teradata’s efficiency in mixed workloads throughput and performance as well as reducing the carbon footprint in cloud data centers.
This is why Teradata has been proven time and again to be the lowest cost data and analytics platform when executing workloads, including the cost of high-speed storage compared to the compute only cost of other cloud analytics platforms. In a recent comprehensive workload comparison [4] based on real-world mixed analytical workloads on competitive systems of comparable configurations, Teradata was measured to be up to 20x cheaper and generate 62 times more throughput than the most marketed cloud analytics platform.
This is due to the level of sophistication in the OCES, IPE, and QRS that optimizes the efficiency of all the resources and extends into workload management by fitting workloads like a Tetris puzzle to ensure all the available resources are delivering maximum value by maintaining high throughput of work and meeting critical SLAs.
The QRS is consulted first to examine patterns and context of the query language and then applies learned best practices while rewriting the SQL before it is submitted to the optimizer. The OCES generates predictive cost estimates and produces possible execution plans and then chooses the plan with the least resource cost. The IPE is adaptive in that it can dynamically acquire new data during run time and feedback to the optimizer to select a more efficient execution plan or generate a new optimized execution plan.
The efficiencies are extended to dataset joins so that new entities can be joined to existing entities within a query to answer new business questions, thereby avoiding the need to redesign or copy data tables that must be flattened to avoid extensive joins that are a significant challenge in inefficient platforms.
Once the plan is selected, the execution plan is generated into an optimized parse tree graph that can also provide natural language explanation of the execution plan known as an EXPLAIN plan.
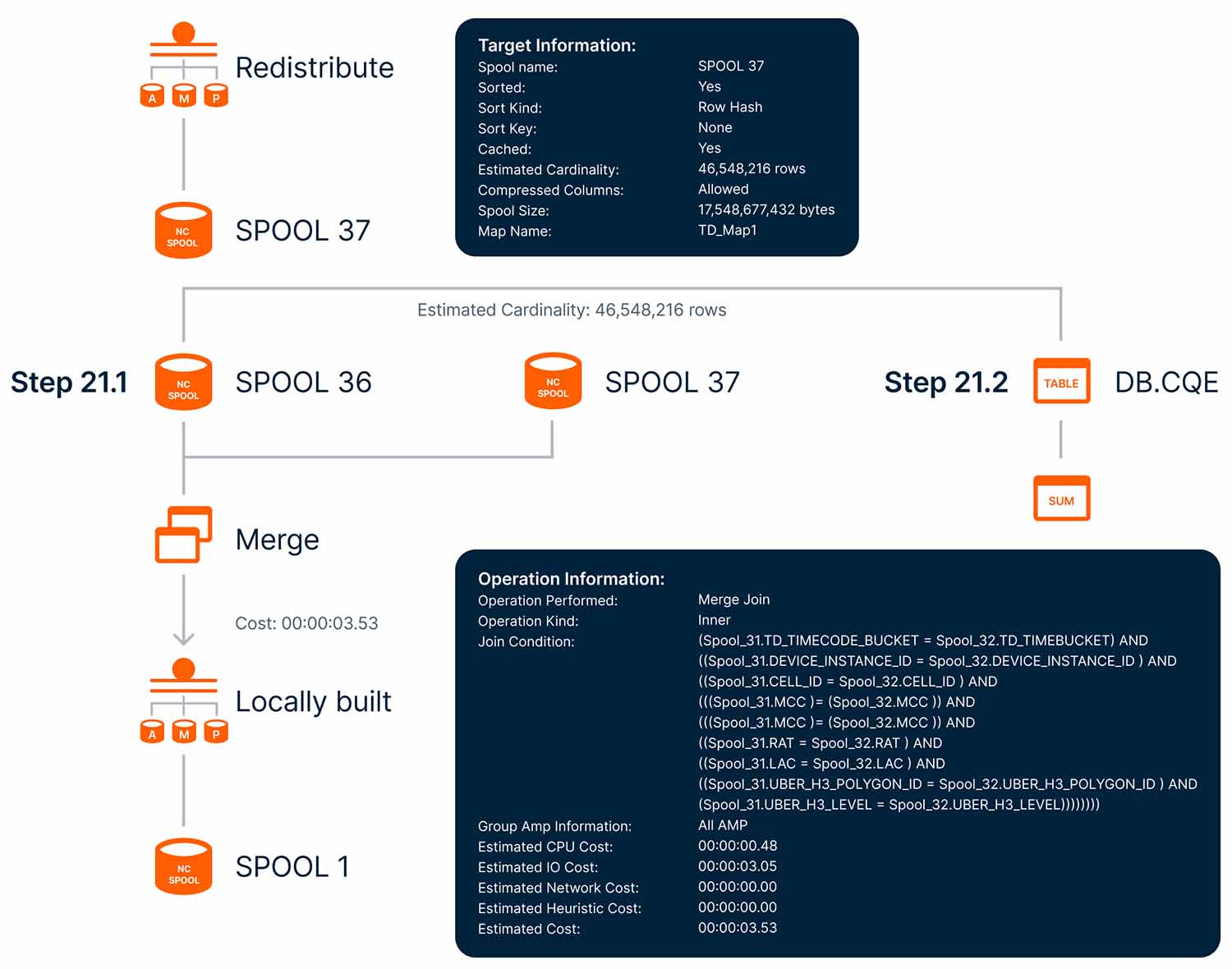
Figure 1: Excerpt from Teradata Visual Explain
Competitive platforms focus their comparisons on the cost of storage which implies data at rest doing nothing. Once workloads are applied, Teradata’s cost estimation ensures that the available resources are used most efficiently to maximize throughput and thereby drastically reduce the frequency to increase compute resources and only scales to add resources when necessary. In other cloud platforms that are unable to apply this level of efficiency the compute costs quickly outpace the storage costs.
The hybrid approach of including object storage with high-speed storage is as efficiently managed to drive lower costs and deliver high value. Estimating the costs of each resource independently provides a dynamic feedback loop that adjusts with the changes occurring within all workloads to eliminate competition for resources.
Teradata’s extensive experience in cost optimization naturally evolved into providing advanced analytics capabilities in the form of Clearscape Analytics. Teradata’s cost optimization therefore provides the lowest cost when using data for analytics.
An Invitation to Join the Future of Analytics
You too can realize extensive cost savings while implementing innovative analytics to propel your business into the future.
Examine for yourself the possibilities of predictive AI techniques, including generative AI use cases by spinning up free Vantage analytics instances at clearscape.teradata.com.
VantageCloud Lake extends the sophistication by maximizing the resources of isolated compute clusters to create on demand innovation labs and robust application platforms in multiple design patterns of Data Warehouse, Data Lake, and Lakehouse.
Combined with open and secured application interfaces across multiple clouds, QueryGrid remote analytics platform interconnects and Native Object Storage (NOS) access to open file formats and open table formats with OCES remote table optimization enhancements you can create an analytic ecosystem positioned for future innovation at the lowest optimized cost.
Take the next step to explore the possibilities of your future by contacting Teradata.
References
[1] Teradata Corporation, "Cost-Based Optimization," October 2023. [Online]. Available: https://docs.teradata.com/r/Enterprise_IntelliFlex_VMware/SQL-Request-and-Transaction-Processing/Query-Rewrite-Statistics-and-Optimization/Cost-Based-Optimization. [Accessed 7 August 2024].
[2] Teradata Corporation, "Incremental Planning and Execution," October 2023. [Online]. Available: https://docs.teradata.com/r/Enterprise_IntelliFlex_VMware/SQL-Request-and-Transaction-Processing/Query-Rewrite-Statistics-and-Optimization/Incremental-Planning-and-Execution. [Accessed 7 August 2024].
[3] Teradata Corporation, "Query Rewrite," October 2023. [Online]. Available: https://docs.teradata.com/r/Enterprise_IntelliFlex_VMware/SQL-Request-and-Transaction-Processing/Query-Rewrite-Statistics-and-Optimization/Query-Rewrite. [Accessed 7 August 2024].
[4] Teradata Corporation, "Achieve more while spending less," [Online]. Available: https://www.teradata.com/why-teradata/workload-comparisons. [Accessed 7 August 2024].